Exposing Ollama LLM
Ollama is a local LLM runner that lets you serve AI models on your own machine. Inspectr makes it easy to expose your Ollama API to the internet for demos, integrations, or remote collaboration.
This guide walks through exposing your Ollama instance securely using Inspectr.
Why Use Inspectr with Ollama?
Section titled “Why Use Inspectr with Ollama?”- Share a live AI model without deploying it
- Inspect and debug request/response cycles
- Secure access with a one-time code
- Replay or log incoming requests
Prerequisites
Section titled “Prerequisites”- Ollama installed and running locally
- Inspectr installed (Install guide →)
Start Ollama locally:
ollama serveFinally, in a separate shell, run a model:
ollama run llama3.2Ollama listens on:
http://localhost:11434Step 1: Start Inspectr in Front of Ollama
Section titled “Step 1: Start Inspectr in Front of Ollama”inspectr \ --backend=http://localhost:11434 \ --expose \ --channel=ollama-demo \ --channel-code=ollama123Inspectr will:
- Forward all traffic from
https://ollama-demo.in-spectr.devto your local Ollama - Log and show all requests/responses in the App UI
- Require callers to include the access code
ollama123
Example Request
Section titled “Example Request”With Inspectr running, you can now send prompts remotely:
curl https://ollama-demo.in-spectr.dev/api/generate \ -d '{ "model": "llama3.2", "prompt": "Why is the sky blue?" }'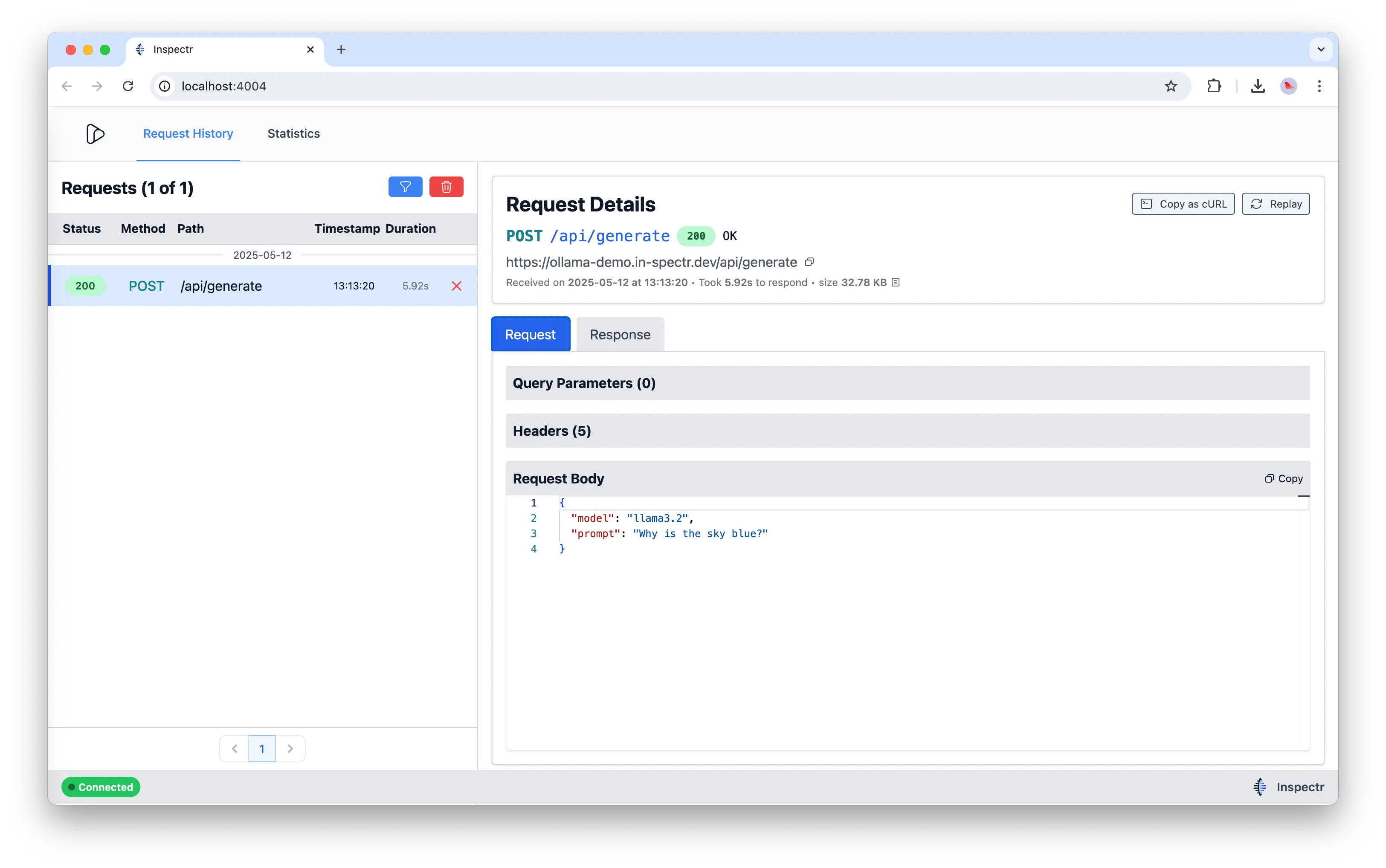
Inspect in Real Time
Section titled “Inspect in Real Time”Use the Inspectr App UI (http://localhost:4004) to:
- Monitor prompts sent to Ollama
- Inspect request headers, bodies, and responses
- Replay past requests to test model behavior
Summary
Section titled “Summary”Inspectr + Ollama is ideal for:
- Sharing demos with teammates or clients
- Testing integration pipelines
- Observing and replaying LLM behavior remotely